
Context Engineering
The discipline that ate prompt engineering, and what it actually means.

A year ago, the most-read piece in this newsletter explained how to phrase a question. Be specific, give the model a role, frame the output. Those rules still hold. They have also become a small piece of a larger discipline that picked up a name last June.
The discipline is called context engineering.
The naming
Tobi Lütke, the CEO of Shopify, posted this on X on June 18, 2025:

Andrej Karpathy, the former OpenAI co-founder and Tesla AI director, weighed in about a week later:
"+1 for 'context engineering' over 'prompt engineering.' People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step."
Andrej Karpathy, on X
By the end of that week, the term had spread to Substack posts, GitHub repos, and conference panels, the usual signs a phrase has caught on. By the fall, Anthropic's engineering team had published a long working definition, and "context engineering" had become the term of art for what people building with AI actually do.
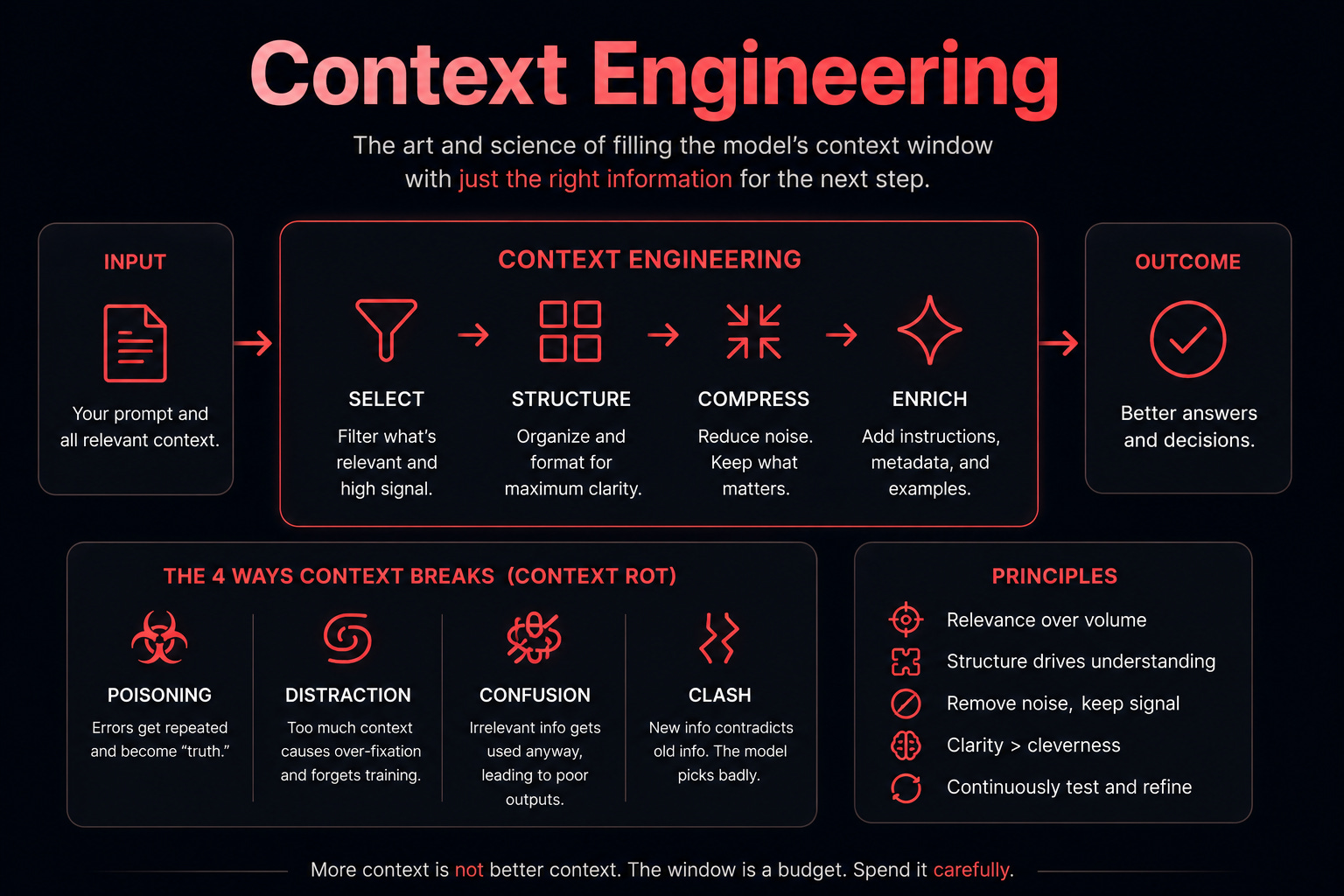
What it means
Anthropic's engineering team published a post in late September 2025, the week Claude Sonnet 4.5 came out, and it remains the cleanest working definition:
"Context engineering is the set of strategies for curating and maintaining the optimal set of tokens during LLM inference."
Anthropic Engineering, "Effective context engineering for AI agents"
The framing is a meaningful change from how the original prompting articles, including the one you read here last spring, talked about the model. Old framing: you say something, the model says something back. New framing: at every step, the model sees a stack of tokens, and your job is to decide what goes into that stack.
The stack includes your prompt. It also includes the system instructions, the retrieved documents, the memory from past sessions, the tool definitions, the tool outputs, the prior turns of the conversation, and any scaffolding the application wraps around all of it.
A prompt is one entry in the stack. Context engineering is about the whole thing.
How it breaks
Drew Breunig, a researcher who has been documenting this work in unusual detail, published a piece in late June 2025 cataloging the four ways context goes wrong. He called the phenomenon context rot, and the names have stuck.
Context poisoning is when a hallucination or factual error gets into the window and then gets referenced repeatedly. Each subsequent turn treats the error as established fact.
Context distraction is when the context grows so long that the model over-fixates on it and stops drawing on what it learned during training.
Context confusion is when irrelevant information in the window gets used anyway, producing a low-quality response.
Context clash is when new information accrues that contradicts something earlier in the stack. The model has to pick a side, and it often picks badly.
The point is that more context is not better context. The window is a budget. Spending it carefully is the work.
What it changes for everyday users
Most people reading this will not build agents or wire up retrieval pipelines. The underlying mindset still matters, because the failure modes show up in regular chats.
If you have ever pasted a long document into a chat and watched the model forget the instructions you gave it at the top, you have seen context distraction. If you have ever fed a model two contradictory versions of a brief and watched it produce something neither of you asked for, that was context clash. If you have ever copied a previous chat's output into a new conversation and watched a hallucination get reinforced into truth, that was poisoning.
The practical shift is from writing better prompts to managing the whole environment the model sees. In a chat interface, that looks like a few small habits. Open a fresh session when the task changes, so context from a marketing brief doesn't bleed into a legal review. Paste only what the model needs; if a document is fifty pages and the question concerns three, paste the three. Treat persistent memory features like Claude Projects, ChatGPT memory, and Gemini gems as part of the context the model sees every time, because they are.
The pushback
Not everyone has accepted that prompt engineering has been superseded. Some practitioners argue the term was hyped before it was useful, and that "context engineering" is the same content with a fresh coat of paint and a bigger word count.
The critique has merit. A lot of what people called prompt engineering in 2023 was a handful of principles in a trench coat. A lot of what people call context engineering in 2026 is broader in scope, but plenty of it is the same principles applied at a wider perimeter.
The cleaner read, from the same Anthropic post, is that prompt engineering did not die. It got reclassified as a subset of context engineering. The wording of the prompt still matters. It is just no longer the whole job.
Where it's heading
If a year ago the question was how to phrase a prompt, this year the question is what should be in the window and what should not. Next year it is likely to be a question about agents. What tools should the model have. What should live in memory. What budget should each step have. What should happen when the model decides on its own to fetch more.
Strategic prompting was the start. Context engineering is the layer above it, and the discipline keeps moving up the stack.